Motivation and Problem Setup¶
We consider the setting where we only have access to a target density known up to a normalization constant
where is the unnormalized density and is the normalization constant, which is generally intractable to compute.
Our aim is to perform a range of inference tasks with respect to , such as:
generating high-quality samples
estimating for a given sample
estimating the entropy of
To accomplish these goals, in practice, we typically rely on a parameterized sampling mechanism, such as a learned sampler, a neural transformation, or a parameterized particle update rule. The quality of inference hinges on how well this mechanism can represent the target density.
Problem Significance¶
This setup arises frequently in machine learning. A motivating example is maximum-entropy reinforcement learning (MaxEnt RL), where policies are defined through unnormalized energy-based distributions over actions.
Policies trained under the maximum-entropy reinforcement learning framework tend to be more robust, as the agent learns to capture multiple modes of high-reward behavior rather than committing to a single deterministic trajectory. Consequently, if the environment or the state is perturbed at test time, the agent is more likely to recover by exploiting alternative high-reward strategies.
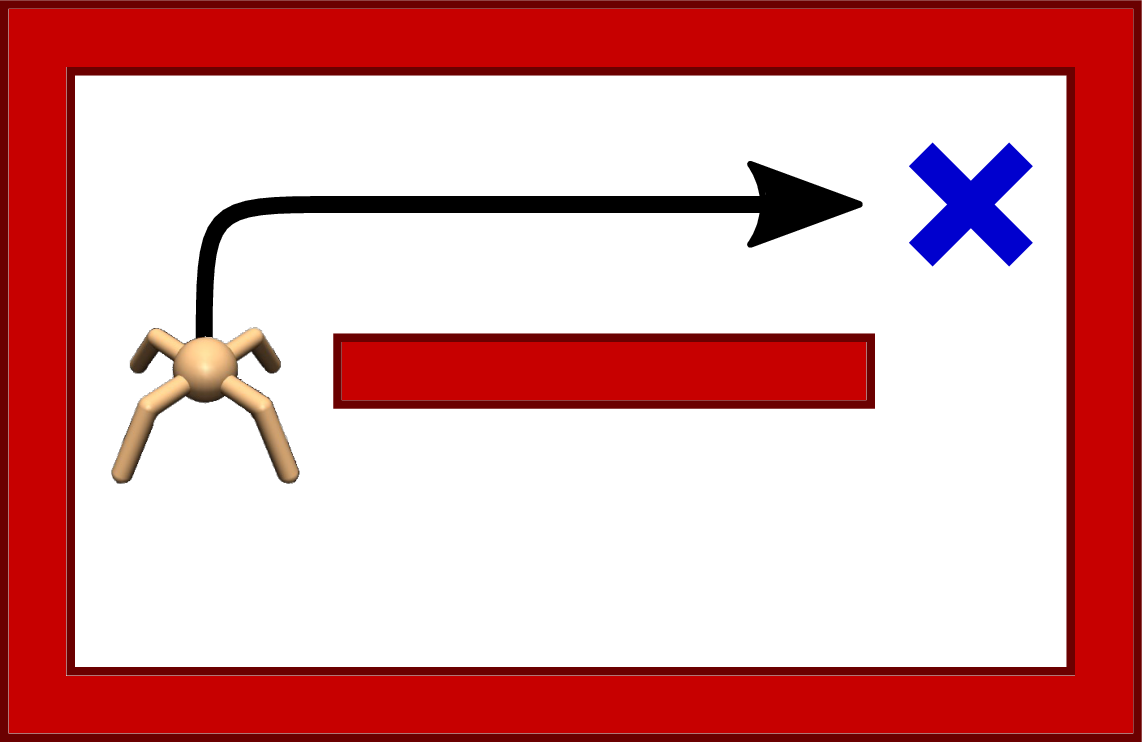
(a)Environment at train time.
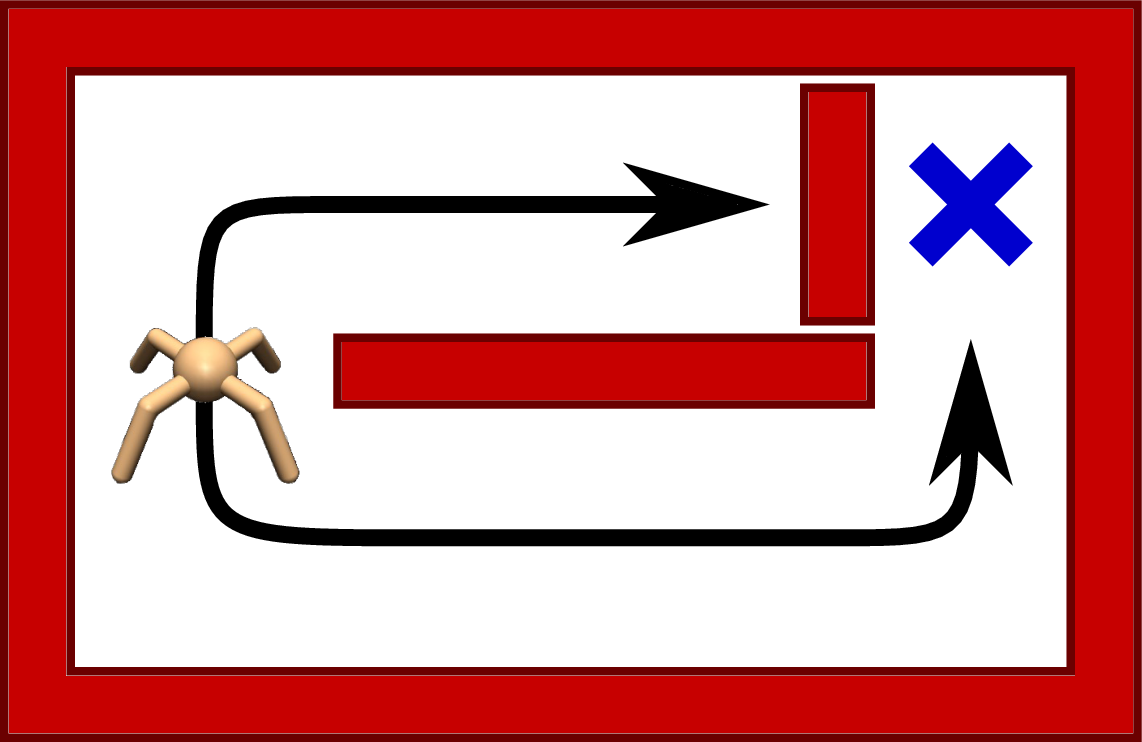
(b)Environment at test time.
Figure 1:https://
This is illustrated in the figure above, where the test time environment includes an additional obstacle that the agent hasn’t seen during training. A standard RL agent that has learned a deterministic policy would not be able to reach the goal, whereas a MaxEnt RL agent would be able to find the lower passage towards the goal.
The Challenge¶
The core difficulty lies in the fact that the normalization constant is unknown, which renders many standard inference methods inapplicable. While can be computed in closed form for certain distributions, such as Gaussians, this is generally not feasible for more complex distributions.
Some methods attempt to approximate , for example via importance sampling, but the variance of these estimates tends to grow with dimensionality, limiting their practicality.
Traditional MCMC methods (e.g., HMC, Langevin dynamics) bypass the normalization constant entirely by using the score function . However, these methods require careful hyperparameter tuning, produce only samples, and often need many iterations to yield high-quality results.
Normalizing flows, by contrast, provide both samples and densities, which allows direct estimation of for a generated sample , and hence also of . Yet, they do not directly leverage the unnormalized density , which limits their expressivity, and are prone to issues such as mode collapse.
What we ultimately seek is a method that constructs a distribution that:
is expressive enough to capture complex, multimodal targets
utilizes the unnormalized density
is computationally tractable
allows efficient sampling
MET-SVGD¶
Metropolis-Hastings Stein Variational Gradient Descent (MET-SVGD) satisfies the above criteria by extending Parameterized SVGD (P-SVGD) Messaoud et al., 2024, a particle-based parametric variational inference method based on SVGD Liu & Wang, 2016 that derives a closed-form expression of the SVGD-induced density.
MET-SVGD bridges the gap between Stein Variational Gradient Descent (SVGD) Liu & Wang, 2016, parametric variational inference (P-VI), and Metropolis-Hastings (MH), inheriting the strengths of each:
the ability to approximate arbitrarily complex distributions, convergence detection, and particle efficiency form SVGD
scalability from P-VI
convergence guarantees from MH
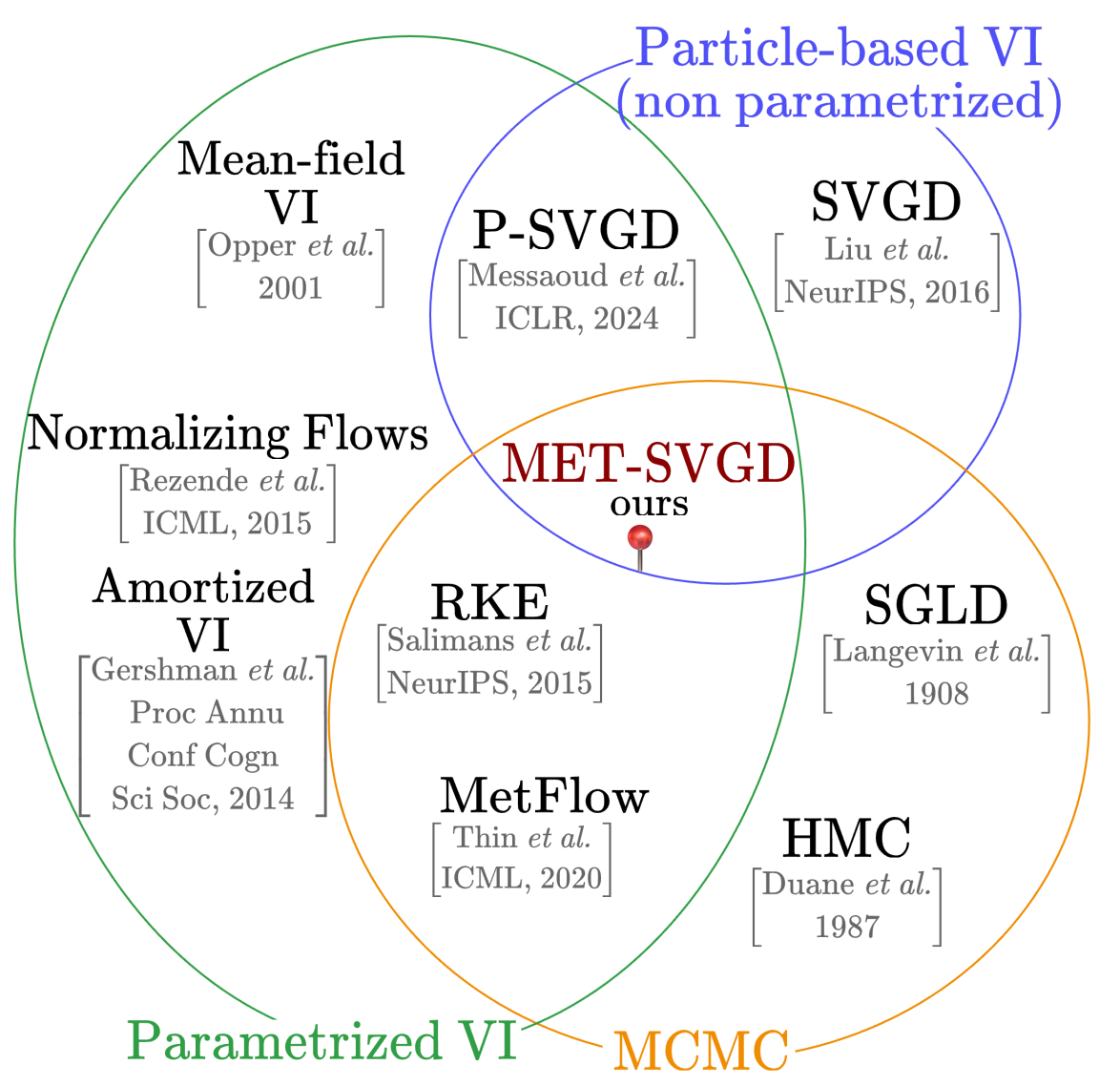
Figure 2:MET-SVGD bridges the gap between P-VI, SVGD, and MCMC methods.
Table 1:MET-SVGD inherits the advantages of different approximate inference methods
| P-VI | MCMC | SVGD | P-SVGD | MET-SVGD | |
|---|---|---|---|---|---|
| Expressivity | ✗ | ✓ | ✓ | ✓ | ✓✓ |
| Convergence Detection | ✓ | ✗ | ✓ | ✓ | ✓ |
| Convergence Guarantees | ✗ | ✓ | ✗ | ✗ | ✓ |
| Sampling Efficiency | ✓ | ✗ | ✓ | ✓ | ✓ |
| Tractable Entropy | ✓ | ✗ | ✗ | ✓ | ✓ |
| Parameter Efficiency | ✓ | — | — | ✓✓ | ✓✓ |
In addition, MET-SVGD unprecedentedly scales SVGD to high-dimensional spaces, while retaining computational efficiency.
Moreover, unlike traditional approaches that rely on grid search for hyperparameter tuning, MET-SVGD enables end-to-end learning of sampler parameters via KL-divergence minimization, solving a long-standing challenge in machine learning.
Finally, MET-SVGD can be viewed as a full-rank Jacobian normalizing flow model with an adaptive number of layers controlled by a convergence check, ensuring flexibility and expressivity.
- Messaoud, S., Mokeddem, B., Xue, Z., Pang, L., An, B., Chen, H., & Chawla, S. (2024). S 2 AC: Energy-Based Reinforcement Learning with Stein Soft Actor Critic. ICLR.
- Liu, Q., & Wang, D. (2016). Stein variational gradient descent: A general purpose bayesian inference algorithm. NeurIPS.